
以前に、以下の記事にて、マッチング処理のロジックについて書かせていただきました。
マッチング処理のロジック – サイゼントの技術ブログ
以前の記事では1対1マッチングと1対nマッチングについて説明しました。
今回の記事では、より複雑なn対nマッチングについて補足します。
1対1マッチングは、マスタデータの1つのキー項目に対して、トランザクションデータの0~1つのレコードが対応するものでした。
1対nマッチングは、マスタデータの1つのキー項目に対して、トランザクションデータの0~複数のレコードが対応するものでした。
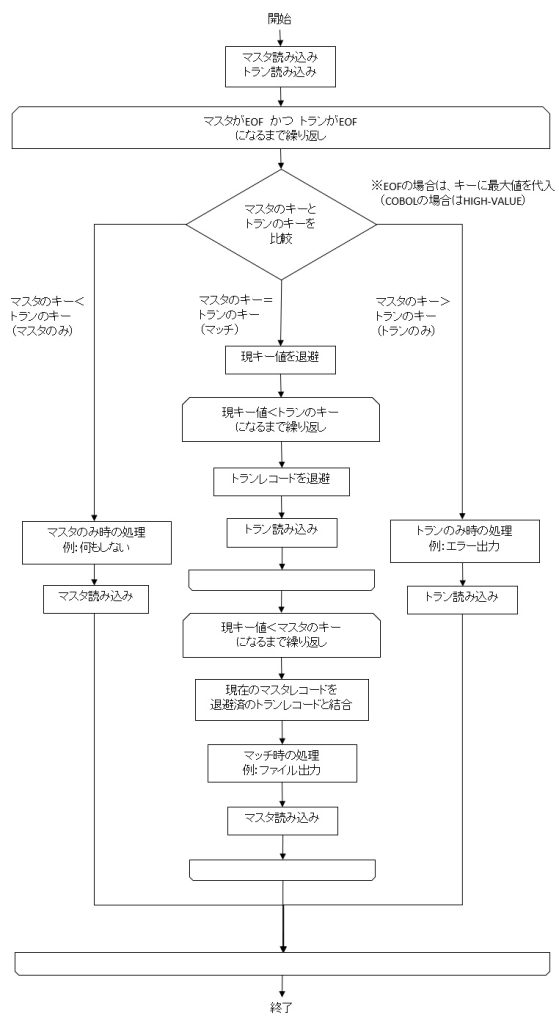
n対nマッチングは、マスタデータ側も1つであるとは限らず、トランザクションデータの1つのキー項目に対して、マスタデータの0~複数のレコードが対応するケースもある、というものを指します。
n対nマッチングでは、以前に参照したトランザクションデータのレコードが、再び参照される可能性があります。
ファイルに対してランダムにアクセスすることでこれを実現できますが、処理が複雑になるため、今回はファイルは順次読み込みのままで、読み込んだトランザクションデータのレコードを一時的に退避するロジックを提示します。
フローチャートと例は以下の通りとなります。
また、この記事に限りませんが、ソースコードをコピペする場合は、「[」を「[」、「]」を「]」、「>」を「>」、「<」を「<」、「&」を「&」に変換するようにお願いします。
【フローチャート】
【例】
・要件
商品名が管理されている商品マスタと、商品の販売履歴(トランザクション)をファイル形式で読み込み、商品名と販売日を別ファイルで出力したい。
・商品マスタのフォーマット
カンマ区切りの固定長ファイル。
商品コードと商品副コードでレコードを一意に特定できるようにデータをセットする。
|
1 2 3 4 5 |
商品コード(7桁) カンマ(1桁) 商品副コード(2桁) カンマ(1桁) 商品名(20桁) |
・販売履歴のフォーマット
カンマ区切りの固定長ファイル。
商品コード・販売日でレコードを一意に特定できるようにデータをセットする。
|
1 2 3 4 5 6 7 |
商品コード(7桁) カンマ(1桁) 販売日(8桁) カンマ(1桁) 販売個数(5桁) カンマ(1桁) 販売金額(9桁) |
・出力ファイルのフォーマット
|
1 2 3 |
商品名(20桁) カンマ(1桁) 販売日(8桁) |
・プログラムのフォルダ構成
|
1 2 3 4 |
execute.bat matching.cs files┬master.csv └transaction.csv |
・ソースコード(execute.bat)
|
1 2 3 4 5 |
@echo off C:\Windows\Microsoft.NET\Framework\v4.0.30319\csc.exe matching.cs matching.exe del matching.exe pause |
・ソースコード(matching.cs)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
using System; using System.Collections; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.IO; namespace Program { class Program { // EOFフラグ static bool isSrmEof = false; static bool isSrtEof = false; static void Main(string[] args) { // ファイルオープン StreamReader srm = new StreamReader (@"files\master.csv", Encoding.UTF8); StreamReader srt = new StreamReader (@"files\transaction.csv", Encoding.UTF8); StreamWriter sw = new StreamWriter (@"files\matched.csv", false, Encoding.UTF8); // 現キー string tmpNowKey; // トランレコード退避用配列 // COBOLの場合は、十分な長さのOCCURS句を定義する、一時ファイルのOPENとCLOSEを繰り返す、等で対応 ArrayList tmpTranRecordList; // 先読みRead string[] mRecord; string[] tRecord; mRecord = mRead(srm); tRecord = tRead(srt); // マッチング処理のループ while (!isSrmEof || !isSrtEof) { // masterのみの場合 if ((!isSrmEof && isSrtEof) || (string.Compare(mRecord[0],tRecord[0]) < 0)) { // 何もしない // master読み込み mRecord = mRead(srm); } // マッチした場合 else if ((!isSrmEof && !isSrtEof) && (string.Compare(mRecord[0],tRecord[0]) == 0)) { // 現キー退避 tmpNowKey = mRecord[0]; // トランレコード退避用配列初期化 tmpTranRecordList = new ArrayList(); // transactionが次のキーに進むまでループ while ((!isSrtEof) && !(string.Compare(tmpNowKey,tRecord[0]) < 0)) { // トランレコード退避 tmpTranRecordList.Add(tRecord[1]); // transaction読み込み tRecord = tRead(srt); } // masterが次のキーに進むまでループ while ((!isSrmEof) && !(string.Compare(tmpNowKey,mRecord[0]) < 0)) { // 退避したトランレコードを順次結合しファイル出力 for (int i = 0; i < tmpTranRecordList.Count; i++) { sw.WriteLine(mRecord[2] + "," + tmpTranRecordList[i]); } // master読み込み mRecord = mRead(srm); } } // transactionのみの場合 else if ((isSrmEof && !isSrtEof) || (string.Compare(mRecord[0],tRecord[0]) > 0)) { // エラー出力 Console.WriteLine("Error:" + tRecord[0] + " is tran only."); // transaction読み込み tRecord = tRead(srt); } } // ファイルクローズ srm.Close(); srt.Close(); sw.Close(); } // MasterファイルRead static string[] mRead(StreamReader srm) { if (srm.Peek() == -1) { isSrmEof = true; return null; } else { string str = srm.ReadLine(); return str.Split(','); } } // TransactionファイルRead static string[] tRead(StreamReader srt) { if (srt.Peek() == -1) { isSrtEof = true; return null; } else { string str = srt.ReadLine(); return str.Split(','); } } } } |
・商品マスタのレコード(files\master.csv)
|
1 2 3 4 5 6 |
0000001,00,hoge 0000002,00,fuga 0000004,01,piyo-Red 0000004,02,piyo-Blue 0000005,01,negi-Miku 0000005,02,negi-Rin |
・販売履歴のレコード(files\transaction.csv)
|
1 2 3 4 5 6 |
0000001,20180401,00100,00010000 0000001,20180402,00200,00020000 0000003,20180401,00001,00001000 0000004,20180401,00002,00002000 0000004,20180402,00004,00004000 0000005,20180401,01000,00100000 |
・バッチ実行結果(標準出力)
|
1 2 3 4 5 6 7 8 |
Microsoft (R) Visual C# Compiler version 4.8.9032.0 for C# 5 Copyright (C) Microsoft Corporation. All rights reserved. This compiler is provided as part of the Microsoft (R) .NET Framework, but only supports language versions up to C# 5, which is no longer the latest version. For compilers that support newer versions of the C# programming language, see http://go.microsoft.com/fwlink/?LinkID=533240 Error:0000003 is tran only. 続行するには何かキーを押してください . . . |
・バッチ実行結果(files\matched.csv)
|
1 2 3 4 5 6 7 8 |
hoge ,20180401 hoge ,20180402 piyo-Red ,20180401 piyo-Red ,20180402 piyo-Blue ,20180401 piyo-Blue ,20180402 negi-Miku ,20180401 negi-Rin ,20180401 |
あけましておめでとうございます!
お久しぶりです。
去年は慌ただしかったので記事を書けずにいましたが、要望があり、再びブログを更新することにしました。
ブログ以外の執筆活動もあるため不定期の更新になりそうですが、折を見て更新を続けていきたいと思います。
改めまして、よろしくお願いします。