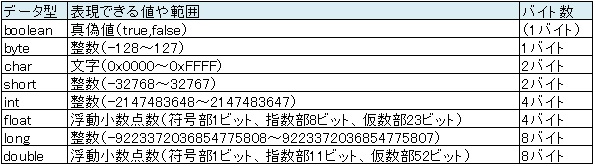
「ソースコードから重複を排除して保守性を高める」という考え方は、実務で良いコードを書く上で重要な考え方です。
この考え方が身に付かない内はオブジェクト指向の理解も不十分になるのですが、いきなりオブジェクト指向から入るとこの考え方の重要性がわかりにくくなることがあります。
そこで、ソースコードから重複を排除することの意義を、関数の使い方から学ぶことが有効になることがあります。
今回は、関数を使うことでソースコードから重複を排除し、保守性が高まる例を挙げていきたいと思います。
(サンプルコードはJavaで記述します)
今回のサンプルコードでは、複数の商品の販売価格を計算します。
まずは関数を使わないサンプルコードから書いていこうと思います。
【サンプルコード(関数未使用・修正前)】
・FunctionTestMain.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
public class FunctionTestMain { public static void main(String[] args) { // 商品の定価 int item1OrginalPrice = 100; int item2OrginalPrice = 200; // 販売額計算 double taxRate = 1.08; double item1SalesPrice = Math.floor(item1OrginalPrice * taxRate); double item2SalesPrice = Math.floor(item2OrginalPrice * taxRate); // 結果表示 System.out.println("item1の販売額:" + item1SalesPrice); System.out.println("item2の販売額:" + item2SalesPrice); } } |
【実行結果】
|
1 2 |
item1の販売額:108.0 item2の販売額:216.0 |
先ほどのソースコードに対して、「店舗独自の割引額を考慮する」という修正を入れていきます。
関数を使用しない場合、割引額(discountRate)を掛けるという修正を複数個所に入れることになります。
これが、ソースコードに重複が発生している状態です。
ソースコードに重複が発生していると、一部だけ修正を漏らすことによるバグに繋がりやすくなります。
このバグを潰すために、テストする範囲も広がってしまいます。
【サンプルコード(関数未使用・修正後)】
・FunctionTestMain.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
public class FunctionTestMain { public static void main(String[] args) { // 商品の定価 int item1OrginalPrice = 100; int item2OrginalPrice = 200; // 販売額計算 double taxRate = 1.08; double discountRate = 0.95; double item1SalesPrice = Math.floor(item1OrginalPrice * taxRate * discountRate); // 修正箇所1 double item2SalesPrice = Math.floor(item2OrginalPrice * taxRate * discountRate); // 修正箇所2 // 結果表示 System.out.println("item1の販売額:" + item1SalesPrice); System.out.println("item2の販売額:" + item2SalesPrice); } } |
【実行結果】
|
1 2 |
item1の販売額:102.0 item2の販売額:205.0 |
次に、ソースコードを一旦修正前の状態に戻して、関数を入れていきます。
販売額を計算する関数(salesPriceCalc)を入れることで、ソースコードから重複を取り除くことができています。
【サンプルコード(関数使用・修正前)】
・FunctionTestMain.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public class FunctionTestMain { public static void main(String[] args) { // 商品の定価 int item1OrginalPrice = 100; int item2OrginalPrice = 200; // 販売額計算 double item1SalesPrice = salesPriceCalc(item1OrginalPrice); double item2SalesPrice = salesPriceCalc(item2OrginalPrice); // 結果表示 System.out.println("item1の販売額:" + item1SalesPrice); System.out.println("item2の販売額:" + item2SalesPrice); } public static double salesPriceCalc(int originalPrice) { double taxRate = 1.08; return Math.floor(originalPrice * taxRate); } } |
【実行結果】
|
1 2 |
item1の販売額:108.0 item2の販売額:216.0 |
関数を使用したソースコードに対して、先ほどと同じように割引額を考慮する修正を入れます。
重複が関数により排除されているので、割引額を入れる修正は1カ所で済んでいます。
修正箇所が減っているため、修正漏れを心配する必要がなくなり、ソースコードの保守が容易になっています。
言い換えると、時間をかけずにバグが出にくい修正を行うことができるようになります。
修正が繰り返される実務のソースコードでは、これは重要なことです。
【サンプルコード(関数使用・修正後)】
・FunctionTestMain.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
public class FunctionTestMain { public static void main(String[] args) { // 商品の定価 int item1OrginalPrice = 100; int item2OrginalPrice = 200; // 販売額計算 double item1SalesPrice = salesPriceCalc(item1OrginalPrice); double item2SalesPrice = salesPriceCalc(item2OrginalPrice); // 結果表示 System.out.println("item1の販売額:" + item1SalesPrice); System.out.println("item2の販売額:" + item2SalesPrice); } public static double salesPriceCalc(int originalPrice) { double taxRate = 1.08; double discountRate = 0.95; return Math.floor(originalPrice * taxRate * discountRate); // 修正箇所1 } } |
【実行結果】
|
1 2 |
item1の販売額:102.0 item2の販売額:205.0 |
今回解説したことは、実際の新人研修でも教えることが多いです。
このような簡単な例を用いることで、ソースコードの重複の排除について、わかりやすく説明することができます。
ところで、突然の発表なのですが、このブログでの私の記事はこれが最後となります。
このブログの記事を読んだことがある、と意外な所から声をかけていただくこともあり、大変嬉しく思っています。
少しでも皆様のお役に立てていたのであれば幸いです。
今まで記事を読んでいただき、ありがとうございました!