
データをメモリに一時的に保持する仕組みとして、スタックとキューがあります。
今回はスタックとキューについて、どのようなものなのかの説明と使い所を書いていきます。
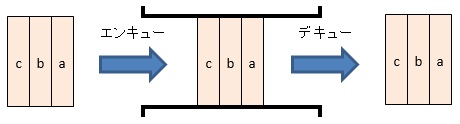
スタックは先入れ後出し、キューは先入れ先出し方式でデータを保持します。
例えば、a,b,cの順番でデータを投入する場合、スタックはc,b,a、キューはa,b,cの順番でデータが取りだされます。
なお、スタックにデータを入れる操作はプッシュ、スタックからデータを取り出す操作はポップ、キューにデータを入れる操作はエンキュー、キューからデータを取り出す操作はデキューと呼びます。
以下、イメージ図です。
・スタック
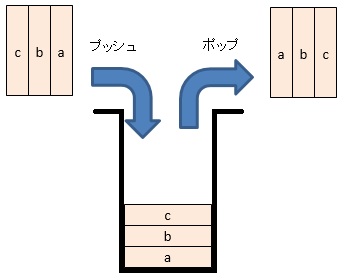
・キュー
スタックが使われる代表的な場面としては、関数呼び出し時に戻り先を保持する場面が挙げられます。
例えば、以下のような構造になっている場合
|
1 2 3 4 5 6 7 8 |
f() { g() //① } g() { h() //② } h() { } |
関数g()が呼び出された時点でスタックに①のアドレス、関数h()が呼び出された時点でスタックに②のアドレスが戻り先として保持されます。
そして、関数h()が終了した時点でスタックから戻り先として②のアドレスが取り出され、関数g()が終了した時点でスタックから戻り先として①のアドレスが取り出されます。
余談ですが、以下のように再帰呼び出しになっている時は注意が必要です。
ループ終了条件を満たさないまま大量の再帰呼び出しを行った場合、戻り先アドレスのサイズがスタックのサイズを超えてしまい、プログラムが異常終了してしまいます。
|
1 2 3 4 5 |
f() { ループ { f() } } |
キューが使われる代表的な場面としては、マルチスレッドの制御を行う場面が挙げられます。
1つのスレッドの処理が「①軽い処理→②重い処理」となっており、かつ①の処理を先に行ったスレッドが②の処理を先に行う必要がある場合、①と②の間にキューを入れて対応します。
①の処理は処理が終わるごとにキューの中にスレッドのオブジェクトを格納し、②の処理は処理が終わる毎にキューの中のスレッドのオブジェクトを取り出し次の処理に移ることで、①の処理と②の処理の速度差を吸収することができます。
いかがでしたでしょうか?
スタックやキューはITパスポートにも出題される基礎的な概念ですが、実際にプログラミングで意識する場面は少ないと思います。
今回の記事では、実際のプログラミングではどのような場面で意識するのかも参考のため書いてみました。


コメント