
C#のコンソールアプリ(コンソール上で動くアプリケーション)をビルド(実行ファイルを作成)して実行手順をまとめてみました。IDEである Visual Studio Community を使う方法と、Windows OS に標準でついてくるコンパイラ csc.exe を使う方法を紹介します。
前者の方法については既にMicrosoftの公式ドキュメント等で公開されているのですが、環境次第では指示通り動かしても上手く動かないことがあるので、私の環境(Windows8.1、Visual Studio Community 2017、元々別件作業で入れたものなのでビルドに関する設定を弄ってしまったかもしれない)で試した手順を参考のため載せます。
(Visual Studio Community のインストール手順は省略します)
後者の方法については、Visual Studio Community が入っていない環境でビルドする際に便利です。
【Visual Studio Community を使う方法】
1.Visual Studio Community を開く。
2.「ファイル > スタートページ」でスタートページを表示させ、スタートページ上の「新しいプロジェクトを作成」をクリック。
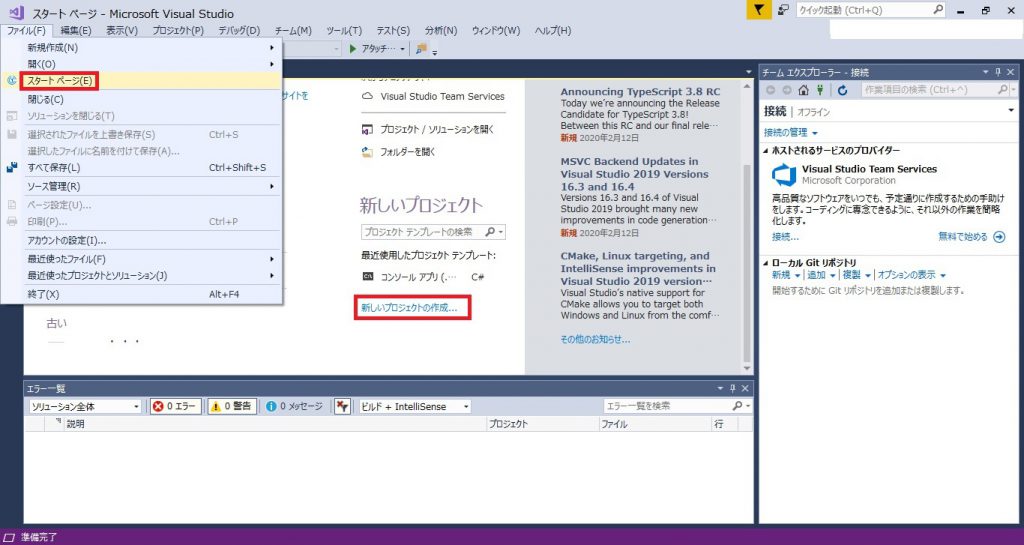
3.「コンソールアプリ」を選択する。名前は任意で良い。これで「OK」を押下すると、「場所」で指定した場所にプロジェクト(作業フォルダ)が生成される。
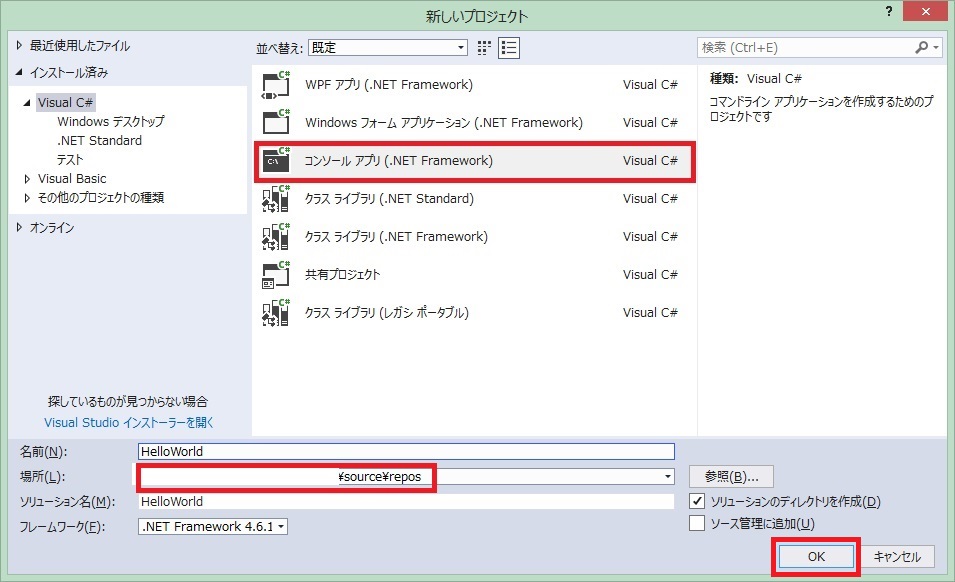
4.ビルド設定を確認する。「プロジェクト > (プロジェクト名)のプロパティ」の「ビルド」リボンでは、どのフォルダに実行ファイルが出力されるのかを確認できる(画面左上)。また、「ツール > オプション」の「プロジェクトおよびソリューション > ビルド/実行」にて、「実行時に、プロジェクトが最新の状態ではないとき」が「常にビルドする」を設定すると、ソースコード等を更新してから実行する際に自動的にビルドされるようになる(画面右下)。
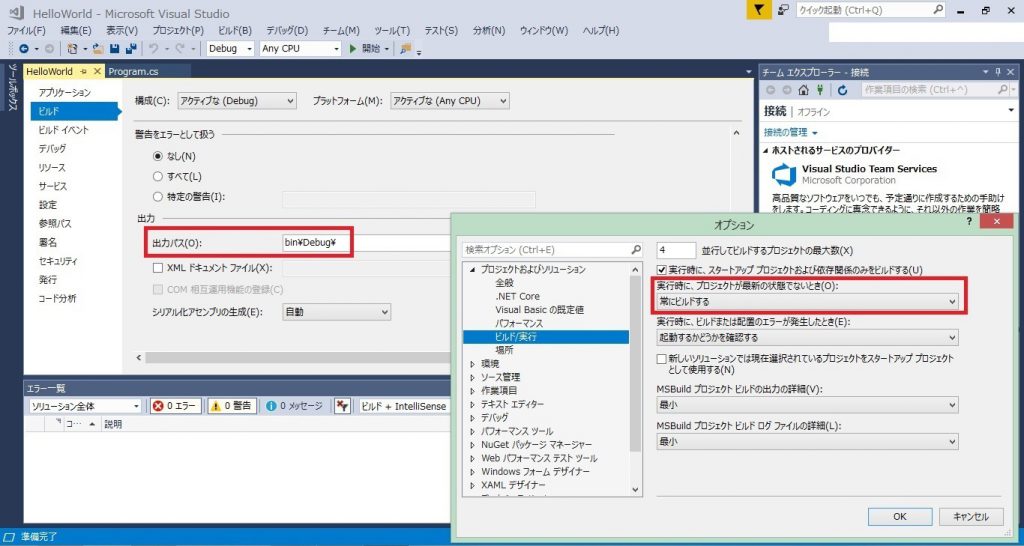
5.「Program.cs」を下記のように書き換え、「ファイル > Program.cs の保存」を押下するか Ctrl+S で保存する。「Console.WriteLine(“Hello World!”);」は画面上に「Hello World!」と出力する命令である。また、「Console.ReadKey(true);」はキーの入力待ちをする命令である(この命令がないと、設定次第では画面上に「Hello World!」と出力されてから一瞬でコンソールが閉じられてしまい、動作を確認できなくなることがある)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace HelloWorld { class Program { static void Main(string[] args) { Console.WriteLine("Hello World!"); Console.ReadKey(true); } } } |
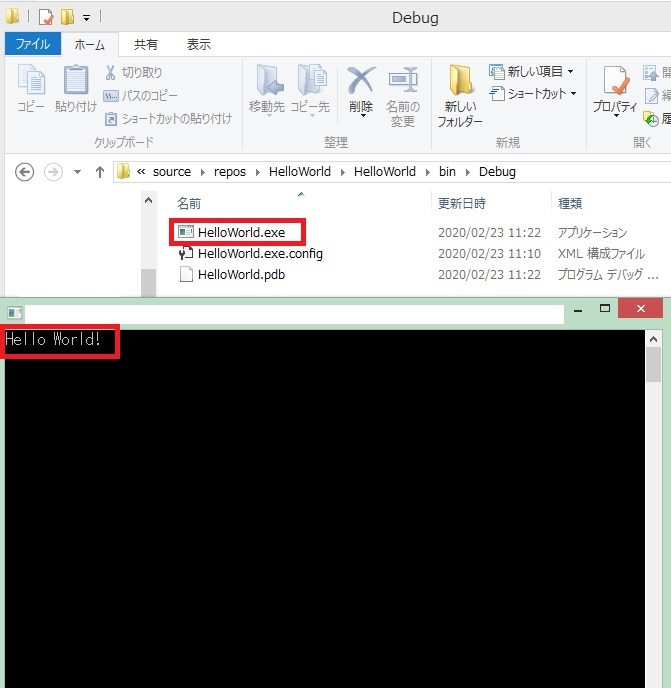
6.「開始」ボタンを押下するかF5キーを押下して実行する。実行すると、4の手順で確認したフォルダに実行ファイル(~.exe)が生成され、コンソール上でプログラムが実行される。以降、実行ファイルをダブルクリックすることで、Visual Studio Community 上でなくてもプログラムを実行することができるようになる(実行ファイルの配布等が可能になる)。
【csc.exe を使う方法】
1.任意のフォルダ(今回は C:\tmp\)で「Program.cs」というファイル名でファイルを作成し、任意のテキストエディタで以下の内容を入力する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace HelloWorld { class Program { static void Main(string[] args) { Console.WriteLine("Hello World!"); Console.ReadKey(true); } } } |
2.「C:\Windows\Microsoft.NET\Framework\v4.0.30319」に「csc.exe」が存在することを確認する。環境次第では「v4.0.30319」というフォルダがないかもしれないので、その場合は別のバージョンのフォルダを使用する。
3.コマンドプロンプトを立ち上げ、1の手順で使用したフォルダへcdコマンドで移動した後、2の手順で確認したcsc.exeを使用してビルドを行う。コマンドとしては下記のように打ち込む。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
c:\>cd c:\tmp c:\tmp>C:\Windows\Microsoft.NET\Framework\v4.0.30319\csc.exe Program.cs Microsoft (R) Visual C# Compiler version 4.7.3062.0 for C# 5 Copyright (C) Microsoft Corporation. All rights reserved. This compiler is provided as part of the Microsoft (R) .NET Framework, but only supports language versions up to C# 5, which is no longer the latest version. Fo r compilers that support newer versions of the C# programming language, see http ://go.microsoft.com/fwlink/?LinkID=533240 c:\tmp> |
4.実行ファイル(Program.exe)が1のフォルダ上に生成されるので、下記のようなコマンドを入力して実行する。なお、実行ファイルを直接ダブルクリックすることでも実行できる。
|
1 2 3 4 |
c:\tmp>Program.exe Hello World! c:\tmp> |
いかがでしたでしょうか?
今回、初めてC#の記事を上げてみました。
文法はjavaに近いので、javaに慣れている方ならC#にも馴染みやすいのではないかと思います。
また、Microsoft社が開発した言語だけあって、Windowsとの相性は抜群で、今回の記事で紹介したようにコンパイラや実行環境もOS標準で入っています。
Windows用のアプリを作りたい時や、Windows向けにちょっとしたツールを作りたい時に適しているのではないかと思います。
今後もC#の記事を上げていきたいと思いますので、よろしくお願いします!